Latest Posts

I came upon Current Ranger from LowPowerLab and have been amazed at how feature-full it is, not to mention the ability to

Watto for iOS A play on watts, the standard unit of power. Watto makes power profiling at the µ-scale easier than before.

A picture is worth 1,000 words. And this is why images are so useful in science communication. The right image only needs

GR/PR on iOS In animal models of limb disuse, grip strength (or force) is a measure used to characterize the time course
Given the important connection between the peripheral and central nervous systems, heart and respiratory rates have become valuable measures to incorporate into
Minimums for visual flight rules (VFR) airspace has always been tricky for me to remember. Popular opinion has Rod Machado’s technique at

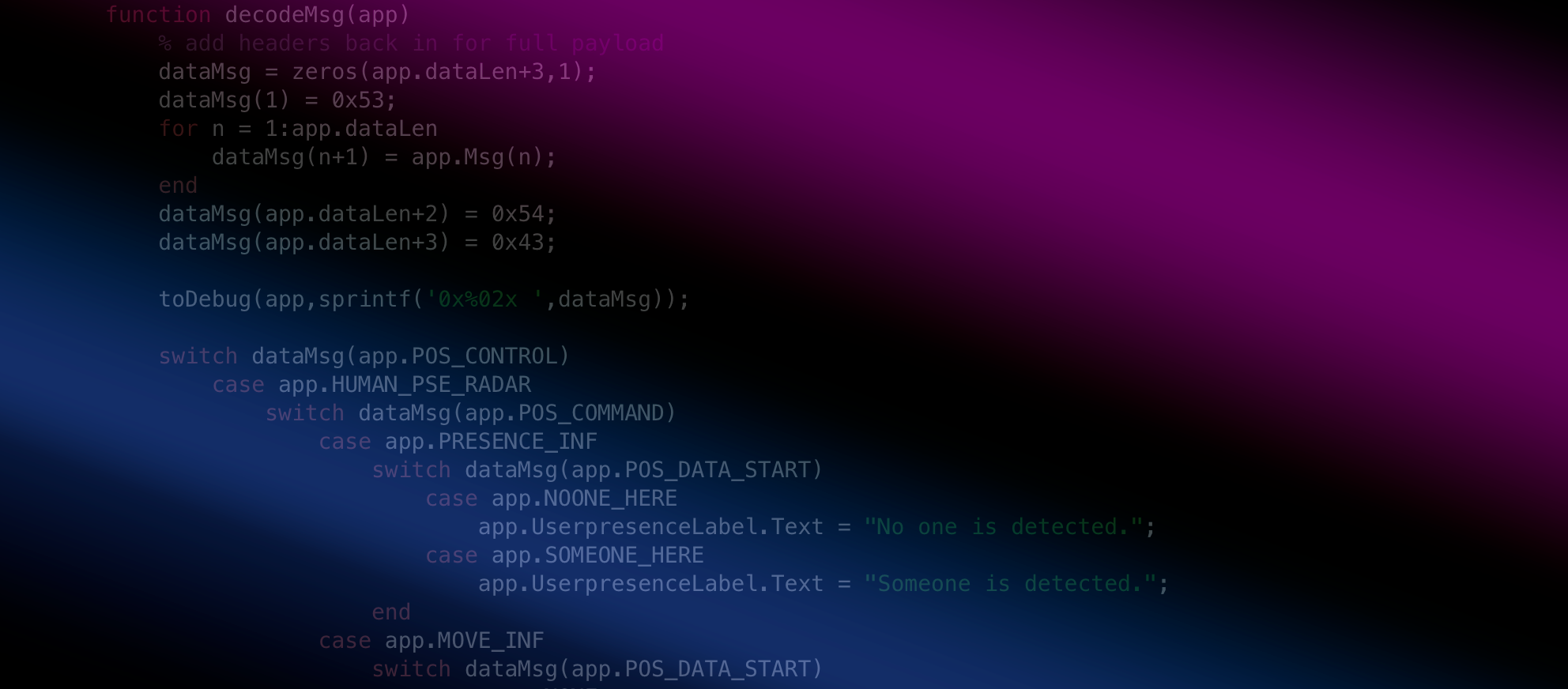
I can’t tell you how many times I have shared a figure from MATLAB using beta-level code and then forgot what file

Hindlimb Unloading Model of Microgravity (see Gnyubkin and Vico, 2015). Load on Forelimbs (left, black) and Tension on Tail (right, red) versus

BLE-enabled bio-loggers make it possible to monitor data and change settings on-the-fly. “ESLO” is our custom bio-logger device that pairs with this
Zero-padding a Fast Fourier Transform (FFT) can increase the resolution of the frequency domain results (see FFT Zero Padding). This is useful